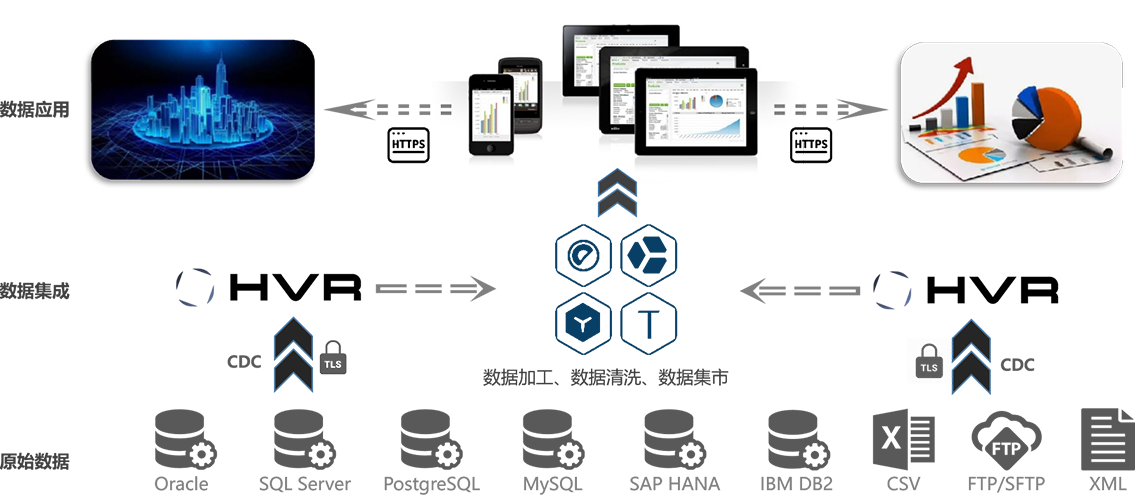
基于HVR+MatrixDB/Teradata/Greenplum/YellowBrick Data的数据底盘解决方案,一站式多数据源的异构集成为金融业、物联网、车联网、工业互联网、智慧城市以及其他行业提供了稳定的、一站式数据平台
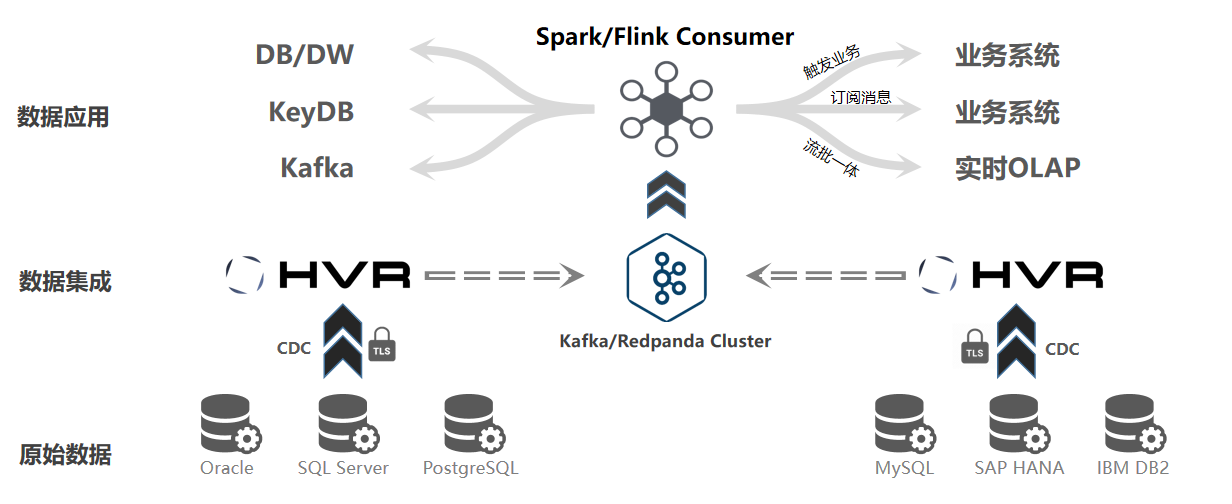
基于HVR+Kafka的业务消息总线解决方案,一站式多数据源异构集成进入Kafka,基于Spark/Flink流计算框架为触发企业相关业务流程、实现实时数据仓库提供支持。

数据进入MatrixDB/YBD/Teradata后,其自带的数据压缩算法,最高可支持1:5的压缩比例,大幅降低了存储资源的投入成本

通过HVR GUI可轻松对数据同步任务进行管理;通过OSS可管理MatrixDB/YBD/Teradata集群环境;与第三方PostgreSQL生态工具很好的集成

查询性能高出Greenplum 5倍以上;SQL开发效率比Greenplum 高10倍;HVR通过强大算力进行数据对比与验证

HVR将业务数据实时集成到MatrixDB/YBD/Teradata ,解决企业数字化转型中的数据孤岛问题

无需Spark、Hadoop、ETL等工具;最佳实践可以在1天内构建稳定的数据底盘供使用
MatrixDB/YBD/Teradata支持PB级的存储与计算;MatrixDB/YBD/Teradata容量支持水平扩展;HVR支持每天10TB以上级数据实时同步
基于HVR+Kafka的业务消息总线解决方案,一站式多数据源异构集成进入Kafka,基于Spark/Flink流计算框架为触发企业相关业务流程、实现实时数据仓库提供支持。
为满足监管数据标准化规范要求,建立监管数据标准化规范(EAST)项目--数据报送模块,实现与数据整合模块及相关系统的接口对接,并实现对EAST所需数据的T+0采集、补录、检核、审核、报送、拆分和存储等功能,保证EAST数据报送的准确性,及时性,完整性。
为了实现上述需求,对数据同步/集成软件有如下要求:
支持十万级数据行集中更新场景下的分钟级内同步
支持亿级数据的稳定全量同步
支持记录源端数据捕获时间
支持记录目标端数据集成时间
支持表结构变更的实时同步
支持断点续传
支持同构/异构数据库向Oracle的数据实时同步
支持Oracle/DB2等其他异构数据库向Kafka的数据实时同步
支持Oracle/DB2等其他异构数据库向Greenplum的数据实时同步
支持Oracle/DB2等其他异构数据库向Hive的数据实时同步
支持数据按表checksum方式校验数据
支持数据逐行逐列校验数据
支持获取数据差异状态信息
支持数据定时/手动校验
支持数据定时自动修复
支持数据手动修复
支持图形化管理多个复制通道
支持图形化监控
支持与第三方系统进行对接
支持管理中心高可用
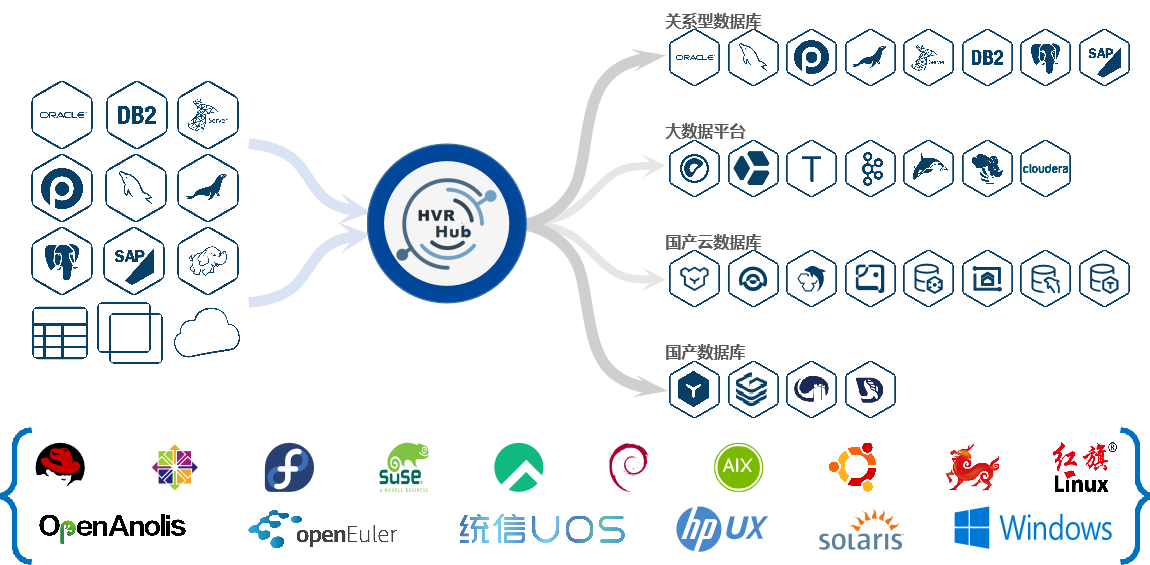
兼容多种操作系统,例如AIX、Linux、Windows、Solaris
兼容国产操作系统,例如中标麒麟、中科红旗、统信OS、华为openEuler